Predicting and Enhancing Student Retention with Big Data

Student retention is one of the largest challenges facing universities. It is strongly correlated to graduation rates, institutional reputation, and financial stability at public and private colleges.
Despite efforts to keep students enrolled, student persistence and graduation rates have shown little change over the past few decades. A significant proportion of students drop out of college in the first year itself, which gives universities little time to intervene.
High first year dropout rates lead to economic implications for colleges, students, and lenders. Between 2003 and 2008, state governments appropriated almost $6.2 billion to help pay for the education of students who did not return to school for a second year.
A key to increasing student retention rates is to identify first year students at risk of dropping out early, so that the institution can provide timely intervention to help those students proceed with their degrees. Traditional survey-based methods of intervention rely on data collected from student questionnaires, which has a number of limitations.
New, innovative work by Anheuser-Busch Chair in MIS, Entrepreneurship, and Innovation and Professor of MIS Sudha Ram, Eller MIS doctoral student Yun Wang, MIS senior lecturer Faiz Currim, and the University of Arizona Alumni Association’s Sabah Currim leverages big data from students’ smart card usage on campus as a means of predicting and enhancing student retention.
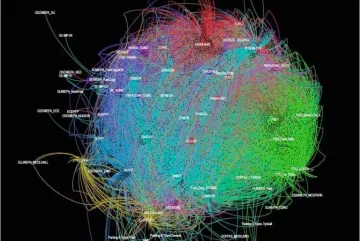
Social interactions among students who do not drop out of college.
“We use the data to measure student social interaction,” says Ram. “For example, we try to figure out how many people students tend to hang out with for different activities, and whether their hanging out drops off week by week or gets stronger.”
Students swipe smart cards at such locations as the gym, library, bookstore, and food court, activities indicative of social integration. More than dropping grades, Ram says, student social interactions indicate whether first years are comfortable, and therefore the likelihood that they will remain or drop out.
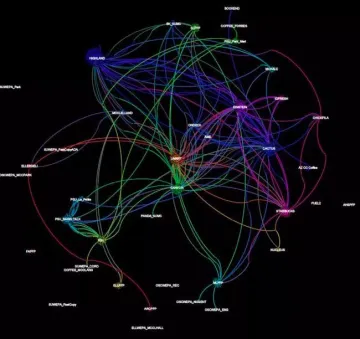
Social interactions among students who do drop out of college.
“Our work also uses quantitative machine learning techniques to proactively predict first year students who are likely to drop out,” she says. “We combine student-related institutional datasets with inferred social (transactions with peers) and behavioral (spatial sequence regularity) signals extracted from smart card transactions.”
These data and techniques have significantly improved the quality of predicting students at risk of dropping out—identifying nearly 90% of first year students who are at risk—and institutions are able to do so well before the end of the first semester. This allows universities to provide timely interventions to students to facilitate increased retention.
Read an article in The New York Times referencing Dr. Ram’s student retention big data project.